此篇博客更倾向于自己的学习心得, 而不是进行OpenGL的教学, 如果你想学习OpenGL请移步LearnOpenGL.
什么是OpenGL?
在ArcVP开发日志中以及介绍过了这一点, 简而言之OpenGL是一个图形API的标准, 各家显卡厂商会自己实现一套OpenGL, 就像是C++标准和不同的编译器之间的关系.
核心模式与立即渲染模式
早期的OpenGL使用立即渲染模式(Immediate mode,也就是固定渲染管线),这个模式下绘制图形很方便。OpenGL的大多数功能都被库隐藏起来,开发者很少有控制OpenGL如何进行计算的自由。而开发者迫切希望能有更多的灵活性。随着时间推移,规范越来越灵活,开发者对绘图细节有了更多的掌控。立即渲染模式确实容易使用和理解,但是效率太低。因此从OpenGL3.2开始,规范文档开始废弃立即渲染模式,并鼓励开发者在OpenGL的核心模式(Core-profile)下进行开发,这个分支的规范完全移除了旧的特性。
当使用OpenGL的核心模式时,OpenGL迫使我们使用现代的函数。当我们试图使用一个已废弃的函数时,OpenGL会抛出一个错误并终止绘图。现代函数的优势是更高的灵活性和效率,然而也更难于学习。立即渲染模式从OpenGL实际运作中抽象掉了很多细节,因此它在易于学习的同时,也很难让人去把握OpenGL具体是如何运作的。现代函数要求使用者真正理解OpenGL和图形编程,它有一些难度,然而提供了更多的灵活性,更高的效率,更重要的是可以更深入的理解图形编程。
这也是为什么我们的教程面向OpenGL3.3的核心模式。虽然上手更困难,但这份努力是值得的。
现今,更高版本的OpenGL已经发布(写作时最新版本为4.5),你可能会问:既然OpenGL 4.5 都出来了,为什么我们还要学习OpenGL 3.3?答案很简单,所有OpenGL的更高的版本都是在3.3的基础上,引入了额外的功能,并没有改动核心架构。新版本只是引入了一些更有效率或更有用的方式去完成同样的功能。因此,所有的概念和技术在现代OpenGL版本里都保持一致。当你的经验足够,你可以轻松使用来自更高版本OpenGL的新特性。
GLAD
因为OpenGL只是一个标准/规范,具体的实现是由驱动开发商针对特定显卡实现的。由于OpenGL驱动版本众多,它大多数函数的位置都无法在编译时确定下来,需要在运行时查询。所以任务就落在了开发者身上,开发者需要在运行时获取函数地址并将其保存在一个函数指针中供以后使用。 而GLAD就是用于简化这一过程的一个库.
着色器
着色器就是能够在GPU上运行的程序, 着色器分为很多种, 每一个着色器只关心渲染或者计算中的一小部分工作, GPU上可以同时运行大量着色器实例, 并且有一部分着色器是可以编程的. 一般来说, 一种着色器的输入通常是另一种着色器的输出. 下面蓝色的是可编程的着色器.
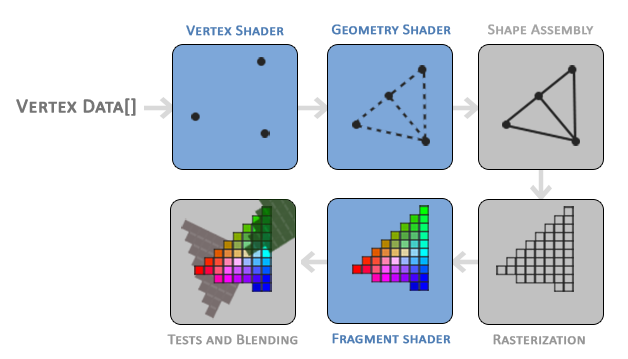
顶点着色器
顶点着色器, 即Vertex Shader, 是几个可编程着色器中的一个. 如果我们打算做渲染的话, 现代OpenGL需要我们至少设置一个顶点和一个片段着色器. 它用于处理每个顶点的数据(如位置、法线、纹理坐标等)。将顶点从模型坐标转换到屏幕坐标,并进行其他顶点相关的变换。一般来说, 顶点着色器就是将空间中的点进行变换到2D平面.
平面上的点不是屏幕上的像素!
几何着色器
顶点着色器阶段的输出可以选择性地传递给几何着色器(Geometry Shader)。几何着色器将一组顶点作为输入,这些顶点形成图元,并且能够通过发出新的顶点来形成新的(或其他)图元来生成其他形状.
图元装配
图元装配(Primitive Assembly)阶段将顶点着色器(或几何着色器)输出的所有顶点作为输入(如果是GL_POINTS,那么就是一个顶点),并将所有的点装配成指定图元的形状.
图元装配阶段的输出会被传入光栅化阶段(Rasterization Stage),这里它会把图元映射为最终屏幕上相应的像素,生成供片段着色器(Fragment Shader)使用的片段(Fragment)。在片段着色器运行之前会执行裁切(Clipping)。裁切会丢弃超出你的视图以外的所有像素,用来提升执行效率。
片段着色器
Fragment Shader, 通常用于结合纹理、光照计算、阴影效果和其他信息,生成每个像素最终的颜色。
在所有对应颜色值确定以后,最终的对象将会被传到最后一个阶段,我们叫做Alpha测试和混合(Blending)阶段。这个阶段检测片段的对应的深度(和模板(Stencil))值,用它们来判断这个像素是其它物体的前面还是后面,决定是否应该丢弃。这个阶段也会检查alpha值(alpha值定义了一个物体的透明度)并对物体进行混合(Blend)。所以,即使在片段着色器中计算出来了一个像素输出的颜色,在渲染多个三角形的时候最后的像素颜色也可能完全不同。
着色器程序
一个着色器Program可以包含上面的一系列Shader, 我们可以将多个Shader Attach 到一个Program上, 然后执行Link操作来生成一个Shader Program管线.
顶点输入
在进行绘制之前, 需要给OpenGL提供一些顶点的坐标. 这些坐标需要位于**[-1~1]** 之间, 这个坐标范围叫做标准化设备坐标. 只有这个范围内的顶点最终才会显示在屏幕上. 这个坐标可以理解为窗口中心为原点的一个笛卡尔坐标.
一旦你的顶点坐标已经在顶点着色器中处理过,它们就应该是标准化设备坐标了,标准化设备坐标是一个x、y和z值在-1.0到1.0的一小段空间。任何落在范围外的坐标都会被丢弃/裁剪,不会显示在你的屏幕上。
使用glViewport函数提供的数据进行视口转换, 可以将标准化设备坐标转化为屏幕空间坐标. 然后被转化为片段送往片段着色器.
Vertex Array
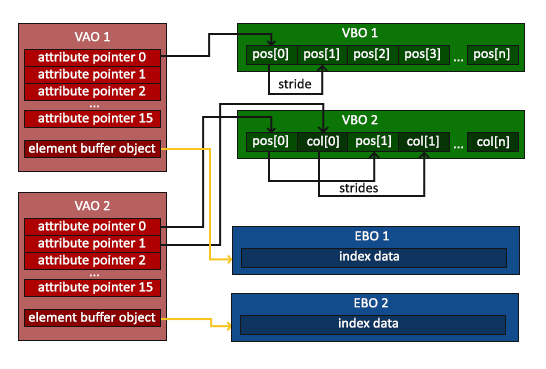 上图是Vertex Array, Vertex Buffer, Element Buffer之间的关系, 一个Vertex Array是我们使用的所有顶点属性的抽象, 其中可以包含多个Attribute Pointer, 指向Vertex Buffer中的具体数据, 这些数据用来描述一个顶点的属性.
上图是Vertex Array, Vertex Buffer, Element Buffer之间的关系, 一个Vertex Array是我们使用的所有顶点属性的抽象, 其中可以包含多个Attribute Pointer, 指向Vertex Buffer中的具体数据, 这些数据用来描述一个顶点的属性.
使用一个缓冲区而不是单独的顶点可以保证, 他们通常被一次发送到GPU的内存中, 将数据从CPU发送到GPU是一个缓慢的过程, 因此我们需要一次发送尽可能多的数据.
而Element Buffer是一个缓冲区,就像Vertex Buffer一样,它存储 OpenGL 用来决定要绘制哪些顶点的索引。这种所谓的索引绘制(Indexed Drawing)正是我们问题的解决方案。
纹理
纹理通俗来讲就是一个游戏里的贴图, 我们会把折叠无缝贴合到模型上, 使得表现出可以复杂的外观.
我们可以使用片段着色器来使用纹理, 首先创建并绑定纹理, 然后为其指定格式并设置数据即可.
在进行纹理数据读取的时候有一个常见的坑, 就是图片数据一般以左上角为坐标原点, 而OpenGL纹理是以左下角为坐标原点, 如果直接使用的话会导致图片上下颠倒, 所以我们需要在读取图像数据的时候进行上下翻转.
纹理过滤
如果说我们将一个纹理应用到一个大小不同的表面上的时候, 就会产生缩放, 我们可以通过设置不同的纹理过滤方式来进行不同的缩放. 比如说使用GL_LINEAR可以使用线性插值, GL_NEAREST可以进行截断.
mipmap
如果每次都使用完整的贴图来应用在一个很小的表面上就会导致开销过大. OpenGL为我们提供了解决方案, 就是mipmap.
它可以理解为预先创建好的不同规格的贴图, 比如你提供一个500x500的贴图, 使用mipmap, OpenGL就可以预先创建好200x200, 50x50大小的贴图, 当我们讲贴图应用于很小的物体上的时候就直接使用50x50大小的变体, 减少计算开销. 同样的, 可以使用GL_NEAREST_MIPMAP_LIENAR来指定使用哪个mipmap变体.
变换
这里需要介绍一些基本的线代:
矩阵乘法
矩阵与矩阵
假设我们称一个x行y列的矩阵为, 则矩阵与之间的相乘需要, 产生的结果为
且矩阵乘法不满足交换律, 即
如下是一个简单的矩阵相乘的实现
template <typename T> using mat = std::vector<std::vector<T>>;
mat<int> matrix_multiply(mat<int> const &lhs, mat<int> const &rhs) {
// Check if matrices are empty
if (lhs.empty() || rhs.empty() || lhs.front().empty() ||
rhs.front().empty()) {
throw std::runtime_error("empty matrix");
}
// Dimensions
int m = lhs.size(); // rows of lhs
int n = lhs.front().size(); // columns of lhs
int p = rhs.size(); // rows of rhs
int q = rhs.front().size(); // columns of rhs
// Check compatibility: n must equal p
if (n != p) {
throw std::runtime_error("matrix dimensions incompatible");
}
// Check consistency of inner vector sizes
for (const auto &row : lhs) {
if (row.size() != n)
throw std::runtime_error("inconsistent lhs column sizes");
}
for (const auto &row : rhs) {
if (row.size() != q)
throw std::runtime_error("inconsistent rhs column sizes");
}
// Result matrix: m × q
mat<int> ret(m, std::vector<int>(q, 0));
// Matrix multiplication
for (int i = 0; i < m; i++) {
for (int j = 0; j < q; j++) {
for (int k = 0; k < n; k++) { // Use n (or p, since n == p)
ret[i][j] += lhs[i][k] * rhs[k][j];
}
}
}
return ret;
}矩阵与向量
同理, 我们可以假设一个n维向量为一个来进行矩阵和向量之间的乘法.
但是为什么我们会关心矩阵能否乘以一个向量?好吧,正巧,很多有趣的2D/3D变换都可以放在一个矩阵中,用这个矩阵乘以我们的向量将变换(Transform)这个向量。如果你仍然有些困惑,我们来看一些例子,你很快就能明白了。
单位矩阵
单位矩阵是一个除了对角线全是0的矩阵, 使用单位矩阵作为变换矩阵可以使一个向量完全不变:
你可能会奇怪一个没变换的变换矩阵有什么用?单位矩阵通常是生成其他变换矩阵的起点,如果我们深挖线性代数,这还是一个对证明定理、解线性方程非常有用的矩阵。
缩放
OpenGL通常是在3D空间进行操作的,对于2D的情况我们可以把z轴缩放1倍,这样z轴的值就不变了。我们刚刚的缩放操作是不均匀(Non-uniform)缩放,因为每个轴的缩放因子(Scaling Factor)都不一样。如果每个轴的缩放因子都一样那么就叫均匀缩放(Uniform Scale)。 如下的变换矩阵可以将一个向量分别进行不同程度的缩放:
注意,第四个缩放向量仍然是1,因为在3D空间中缩放w分量是无意义的。w分量另有其他用途,在后面我们会看到。
位移
位移(Translation)是在原始向量的基础上加上另一个向量从而获得一个在不同位置的新向量的过程,从而在位移向量基础上移动了原始向量。我们已经讨论了向量加法,所以这应该不会太陌生。
有了位移矩阵我们就可以在3个方向(x, y, z)上移动物体,它是我们的变换工具箱中非常有用的一个变换矩阵。
旋转
在3D空间中旋转需要定义一个角和一个旋转轴(Rotation Axis)。物体会沿着给定的旋转轴旋转特定角度。如果你想要更形象化的感受,可以试试向下看着一个特定的旋转轴,同时将你的头部旋转一定角度。当2D向量在3D空间中旋转时,我们把旋转轴设为z轴(尝试想象这种情况) 旋转矩阵在3D空间中每个单位轴都有不同定义,旋转角度用表示:
利用旋转矩阵我们可以把任意位置向量沿一个单位旋转轴进行旋转。也可以将多个矩阵复合,比如先沿着x轴旋转再沿着y轴旋转。但是这会很快导致一个问题——万向节死锁。在这里我们不会讨论它的细节,但是对于3D空间中的旋转,一个更好的模型是沿着任意的一个轴,比如单位向量旋转,而不是对一系列旋转矩阵进行复合.
避免万向节死锁的真正解决方案是使用四元数(Quaternion),它不仅更安全,而且计算会更有效率。
矩阵的结合
通过上面介绍的不同的变换矩阵, 我们就可以对一个向量在空间中进行任意变换. 根据矩阵之间的乘法, 我们可以将多个变换矩阵结合到一个矩阵中
当矩阵相乘时我们通常先写位移再写缩放变换。 矩阵乘法是不遵守交换律的,这意味着它们的顺序很重要。当矩阵相乘时,在最右边的矩阵是第一个与向量相乘的,所以你应该从右向左读这个乘法。 建议您在组合矩阵时,先进行缩放操作,然后是旋转,最后才是位移,否则它们会(消极地)互相影响。 比如,如果你先位移再缩放,位移的向量也会同样被缩放!
坐标空间
将坐标变换为标准化设备坐标,接着再转化为屏幕坐标的过程通常是分步进行的,也就是类似于流水线那样子。在流水线中,物体的顶点在最终转化为屏幕坐标之前还会被变换到多个坐标系统(Coordinate System)。将物体的坐标变换到几个过渡坐标系(Intermediate Coordinate System)的优点在于,在这些特定的坐标系统中,一些操作或运算更加方便和容易,这一点很快就会变得很明显。对我们来说比较重要的总共有5个不同的坐标系统:
- 局部空间(Local Space,或者称为物体空间(Object Space))
- 世界空间(World Space)
- 观察空间(View Space,或者称为视觉空间(Eye Space))
- 裁剪空间(Clip Space)
- 屏幕空间(Screen Space)
为了将坐标从一个坐标系变换到另一个坐标系,我们需要用到几个变换矩阵,最重要的几个分别是模型(Model)、观察(View)、投影(Projection)三个矩阵。我们的顶点坐标起始于局部空间(Local Space),在这里它称为局部坐标(Local Coordinate),它在之后会变为世界坐标(World Coordinate),观察坐标(View Coordinate),裁剪坐标(Clip Coordinate),并最后以屏幕坐标(Screen Coordinate)的形式结束。下面的这张图展示了整个流程以及各个变换过程做了什么:
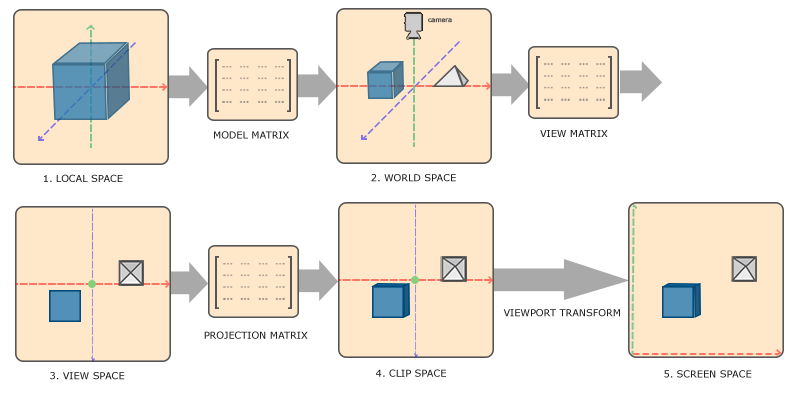
- 局部坐标是对象相对于局部原点的坐标,也是物体起始的坐标。
- 下一步是将局部坐标变换为世界空间坐标,世界空间坐标是处于一个更大的空间范围的。这些坐标相对于世界的全局原点,它们会和其它物体一起相对于世界的原点进行摆放。
- 接下来我们将世界坐标变换为观察空间坐标,使得每个坐标都是从摄像机或者说观察者的角度进行观察的。
- 坐标到达观察空间之后,我们需要将其投影到裁剪坐标。裁剪坐标会被处理至-1.0到1.0的范围内,并判断哪些顶点将会出现在屏幕上。
- 最后,我们将裁剪坐标变换为屏幕坐标,我们将使用一个叫做视口变换(Viewport Transform)的过程。视口变换将位于-1.0到1.0范围的坐标变换到由
glViewport函数所定义的坐标范围内。最后变换出来的坐标将会送到光栅器,将其转化为片段。
局部空间
局部空间是指物体所在的坐标空间,即对象最开始所在的地方。想象你在一个建模软件(比如说Blender)中创建了一个立方体。你创建的立方体的原点有可能位于(0, 0, 0),即便它有可能最后在程序中处于完全不同的位置。甚至有可能你创建的所有模型都以(0, 0, 0)为初始位置(译注:然而它们会最终出现在世界的不同位置)。所以,你的模型的所有顶点都是在局部空间中:它们相对于你的物体来说都是局部的。
世界空间
如果我们将所有的物体导入到程序当中,它们有可能会全挤在世界的原点(0, 0, 0)上,这并不是我们想要的结果。我们想为每一个物体定义一个位置,从而能在更大的世界当中放置它们。世界空间中的坐标正如其名:是指顶点相对于(游戏)世界的坐标。如果你希望将物体分散在世界上摆放(特别是非常真实的那样),这就是你希望物体变换到的空间。物体的坐标将会从局部变换到世界空间;该变换是由模型矩阵(Model Matrix)实现的。
模型矩阵是一种变换矩阵,它能通过对物体进行位移、缩放、旋转来将它置于它本应该在的位置或朝向。你可以将它想像为变换一个房子,你需要先将它缩小(它在局部空间中太大了),并将其位移至郊区的一个小镇,然后在y轴上往左旋转一点以搭配附近的房子。你也可以把上一节将箱子到处摆放在场景中用的那个矩阵大致看作一个模型矩阵;我们将箱子的局部坐标变换到场景/世界中的不同位置。
观察空间
观察空间经常被人们称之OpenGL的摄像机(Camera)(所以有时也称为摄像机空间(Camera Space)或视觉空间(Eye Space))。观察空间是将世界空间坐标转化为用户视野前方的坐标而产生的结果。因此观察空间就是从摄像机的视角所观察到的空间。而这通常是由一系列的位移和旋转的组合来完成,平移/旋转场景从而使得特定的对象被变换到摄像机的前方。这些组合在一起的变换通常存储在一个观察矩阵(View Matrix)里,它被用来将世界坐标变换到观察空间。在下一节中我们将深入讨论如何创建一个这样的观察矩阵来模拟一个摄像机。
当我们使用model,view和projection矩阵相乘得到的矩阵与一个向量进行乘法, 得到的结果就是裁剪空间中对应的向量. 但是这个矩阵乘积与向量带来的影响是逆序的, 也就是与向量的乘积相当于先对向量进行projection变换, 而不是model变换, 这样的结果是不符合预期的, 因此我们需要将其逆序相乘, 即.
裁剪空间
在一个顶点着色器运行的最后,OpenGL期望所有的坐标都能落在一个特定的范围内,且任何在这个范围之外的点都应该被裁剪掉(Clipped)。被裁剪掉的坐标就会被忽略,所以剩下的坐标就将变为屏幕上可见的片段。这也就是裁剪空间(Clip Space)名字的由来。
为了将顶点坐标从观察变换到裁剪空间,我们需要定义一个投影矩阵(Projection Matrix),它指定了一个范围的坐标,比如在每个维度上的-1000到1000。投影矩阵接着会将在这个指定的范围内的坐标变换为标准化设备坐标的范围(-1.0, 1.0)。所有在范围外的坐标不会被映射到在-1.0到1.0的范围之间,所以会被裁剪掉。在上面这个投影矩阵所指定的范围内,坐标(1250, 500, 750)将是不可见的,这是由于它的x坐标超出了范围,它被转化为一个大于1.0的标准化设备坐标,所以被裁剪掉了。
如果只是图元(Primitive),例如三角形,的一部分超出了裁剪体积(Clipping Volume),则OpenGL会重新构建这个三角形为一个或多个三角形让其能够适合这个裁剪范围。
一种常见的做法是每一帧在CPU端计算矩阵, 将结果和矩阵一起传送到GPU, 因为场景内的每个物体这两个矩阵乘的结果都是相同的, 所以这样减小了GPU重复计算的开销. 对于CPU来说, 计算矩阵是廉价的, 因为CPU只需要每帧计算一次, 而GPU需要每个顶点每帧计算一次. 而且从CPU发送数据到GPU可能是性能瓶颈, 我们需要尽可能少的发送数据.
由投影矩阵创建的观察箱(Viewing Box)被称为平截头体(Frustum),每个出现在平截头体范围内的坐标都会最终出现在用户的屏幕上。将特定范围内的坐标转化到标准化设备坐标系的过程(而且它很容易被映射到2D观察空间坐标)被称之为投影(Projection),因为使用投影矩阵能将3D坐标投影(Project)到很容易映射到2D的标准化设备坐标系中。
一旦所有顶点被变换到裁剪空间,最终的操作——透视除法(Perspective Division)将会执行,在这个过程中我们将位置向量的x,y,z分量分别除以向量的齐次w分量;透视除法是将4D裁剪空间坐标变换为3D标准化设备坐标的过程。这一步会在每一个顶点着色器运行的最后被自动执行。
在这一阶段之后,最终的坐标将会被映射到屏幕空间中(使用glViewport中的设定),并被变换成片段。
将观察坐标变换为裁剪坐标的投影矩阵可以为两种不同的形式,每种形式都定义了不同的平截头体。我们可以选择创建一个正射投影矩阵(Orthographic Projection Matrix)或一个透视投影矩阵(Perspective Projection Matrix)。
正射投影
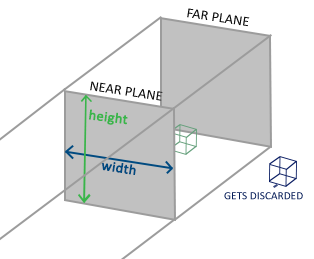
正射投影矩阵定义的平截头体类似于一个立方体, 需要知道长宽高. 只有在这个容器范围之内才不会被裁剪掉. 正射平截头体直接将平截头体内部的所有坐标映射为标准化设备坐标,因为每个向量的w分量都没有进行改变;如果w分量等于1.0,透视除法则不会改变这个坐标。
正射投影矩阵直接将坐标映射到2D平面中,即你的屏幕,但实际上一个直接的投影矩阵会产生不真实的结果,因为这个投影没有将透视(Perspective)考虑进去。所以我们需要透视投影矩阵来解决这个问题。
透视投影
一个透视平截头体可以被看作一个不均匀形状的箱子,在这个箱子内部的每个坐标都会被映射到裁剪空间上的一个点。下面是一张透视平截头体的图片:
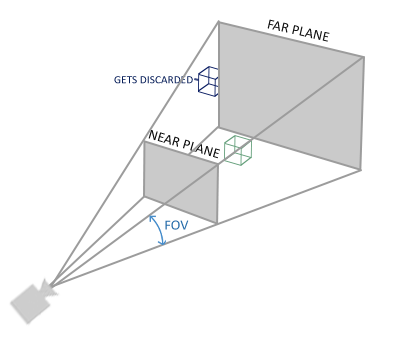 如果我们需要近大远小的效果, 就需要使用透视投影, 这个投影矩阵将给定的平截头体范围映射到裁剪空间,除此之外还修改了每个顶点坐标的w值,从而使得离观察者越远的顶点坐标w分量越大。被变换到裁剪空间的坐标都会在-w到w的范围之间(任何大于这个范围的坐标都会被裁剪掉)。OpenGL要求所有可见的坐标都落在-1.0到1.0范围内,作为顶点着色器最后的输出,因此,一旦坐标在裁剪空间内之后,透视除法就会被应用到裁剪空间坐标上:
如果我们需要近大远小的效果, 就需要使用透视投影, 这个投影矩阵将给定的平截头体范围映射到裁剪空间,除此之外还修改了每个顶点坐标的w值,从而使得离观察者越远的顶点坐标w分量越大。被变换到裁剪空间的坐标都会在-w到w的范围之间(任何大于这个范围的坐标都会被裁剪掉)。OpenGL要求所有可见的坐标都落在-1.0到1.0范围内,作为顶点着色器最后的输出,因此,一旦坐标在裁剪空间内之后,透视除法就会被应用到裁剪空间坐标上:
顶点坐标的每个分量都会除以它的w分量,距离观察者越远顶点坐标就会越小。这是w分量重要的另一个原因,它能够帮助我们进行透视投影。最后的结果坐标就是处于标准化设备空间中的。
LookAt
使用矩阵的好处之一是如果你使用3个相互垂直(或非线性)的轴定义了一个坐标空间,你可以用这3个轴外加一个平移向量来创建一个矩阵,并且你可以用这个矩阵乘以任何向量来将其变换到那个坐标空间。这正是LookAt矩阵所做的,现在我们有了3个相互垂直的轴和一个定义摄像机空间的位置坐标,我们可以创建我们自己的LookAt矩阵了:
其中R是右向量,U是上向量,D是方向向量P是摄像机位置向量。注意,位置向量是相反的,因为我们最终希望把世界平移到与我们自身移动的相反方向。把这个LookAt矩阵作为观察矩阵可以很高效地把所有世界坐标变换到刚刚定义的观察空间。LookAt矩阵就像它的名字表达的那样:它会创建一个看着(Look at)给定目标的观察矩阵。
一种特殊类型的观察矩阵,它创建了一个坐标系,其中所有坐标都根据从一个位置正在观察目标的用户旋转或者平移。
欧拉角
被定义为偏航角(Yaw),俯仰角(Pitch),和滚转角(Roll)从而允许我们通过这三个值构造任何3D方向。